PDFXplorer Features
PDFXplorer is a flexible application that lets you explore the internals of any PDF file. It shows the PDF file in a tree structure, matching the PDF structure in the file. It can be used to debug a wide range of PDF problems, from invalid references to damaged page content. PDFXplorer supports all PDF versions, its PDF engine being version independent. Also encrypted PDF files are supported. PDFXplorer toolkit has been developed entirely in C#, being 100% managed code.
Free License for both personal and commercial use
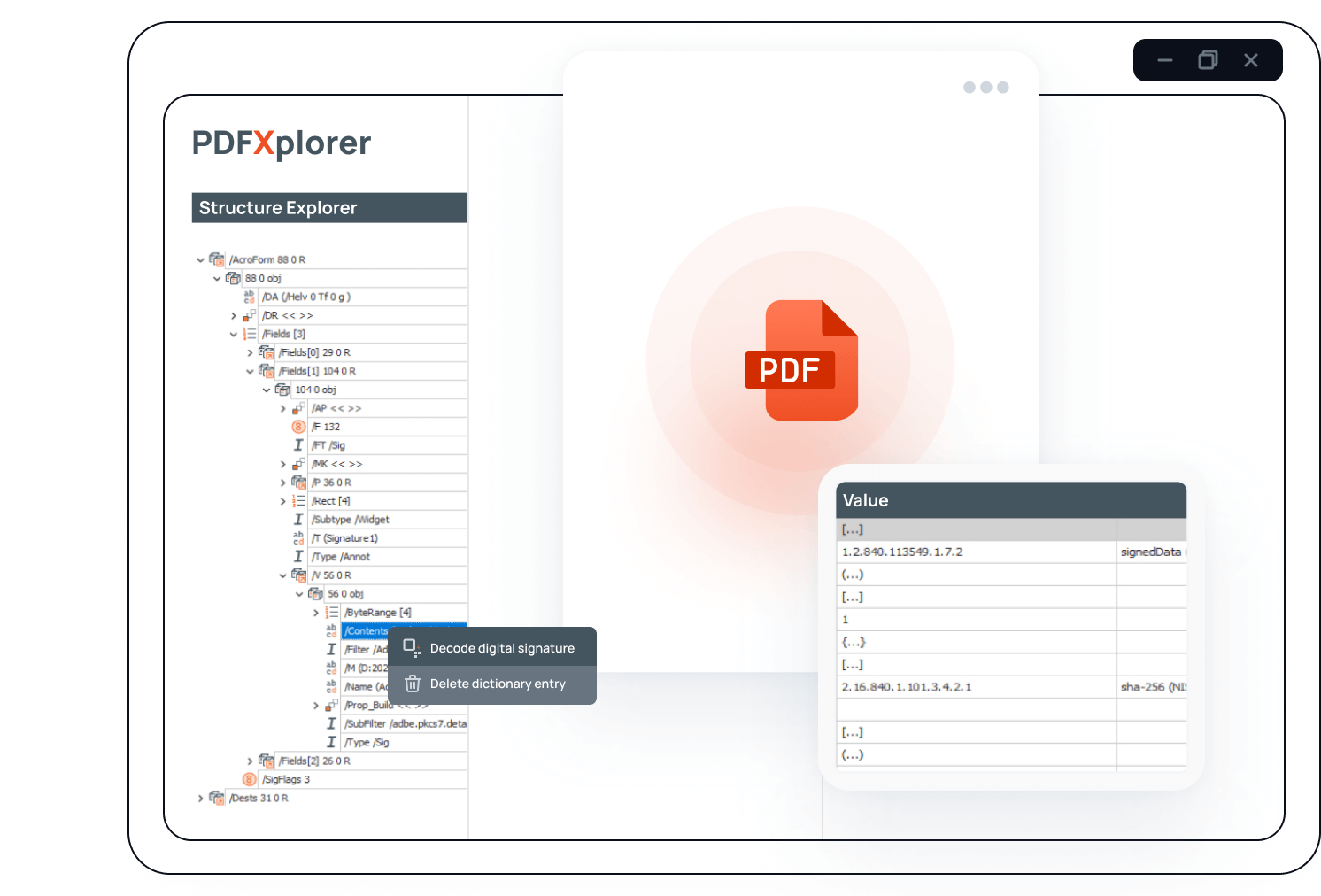

Low Level Features
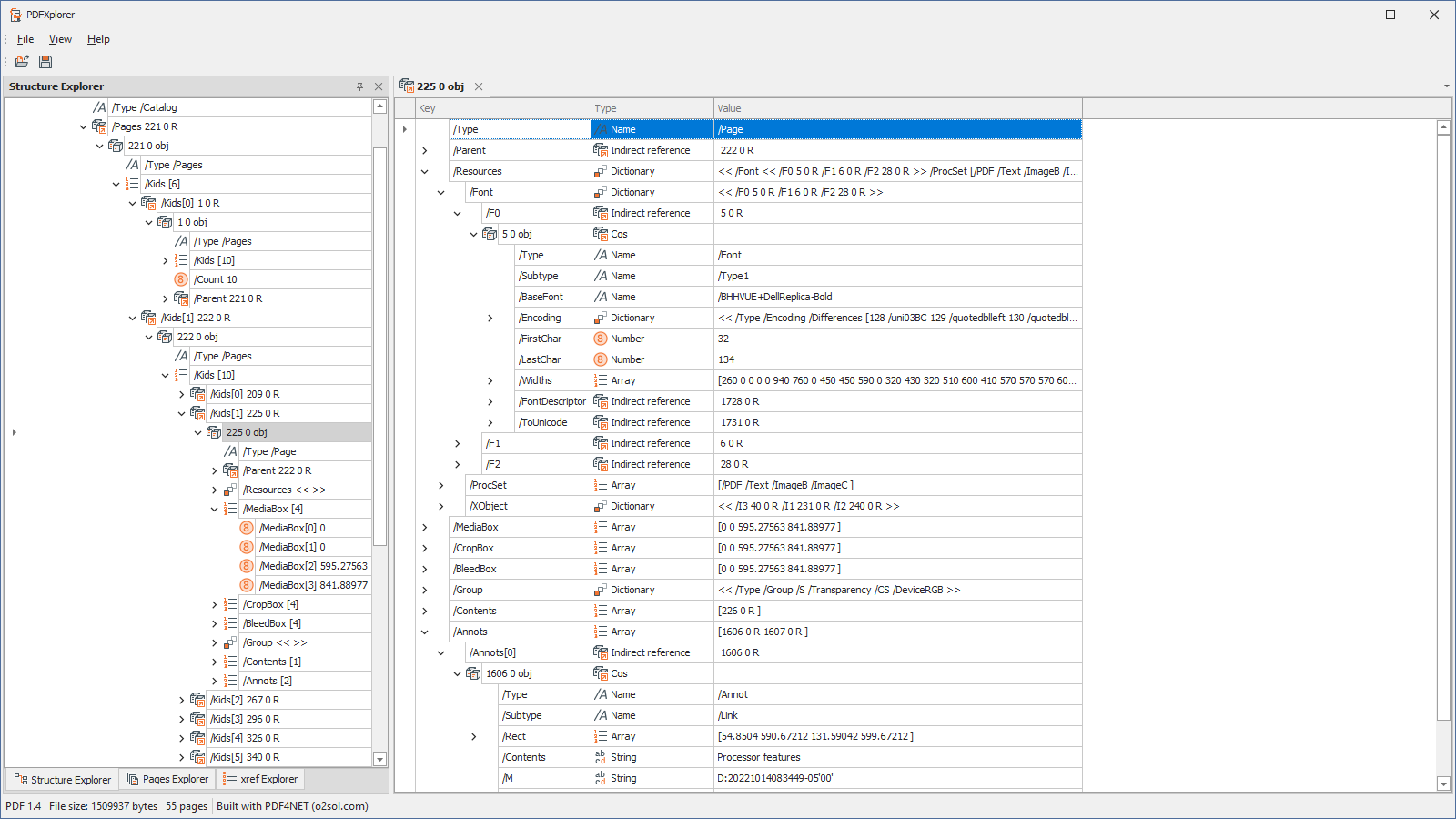
- View PDF file structure as a tree of COS objects in the Structure Explorer
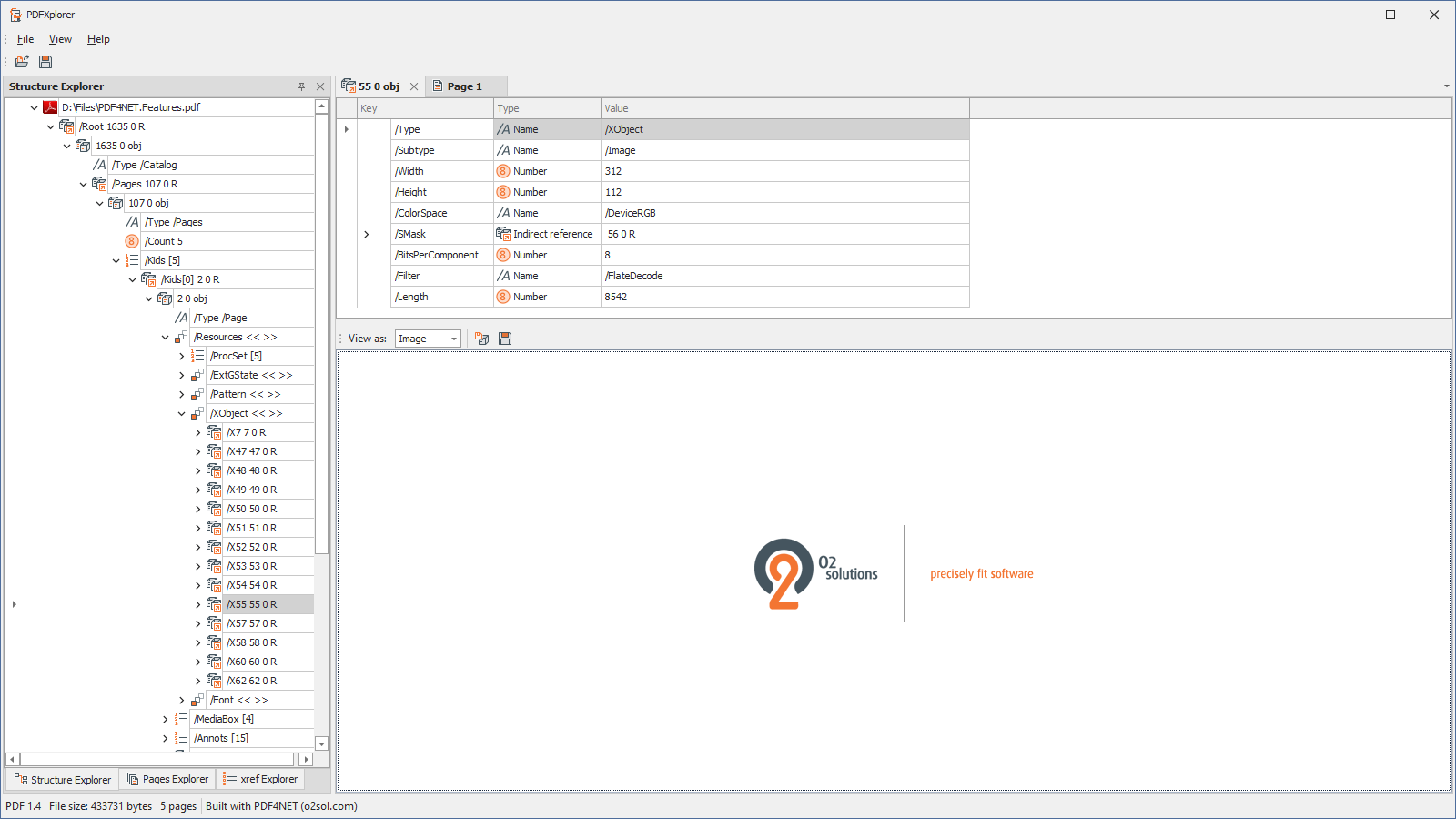
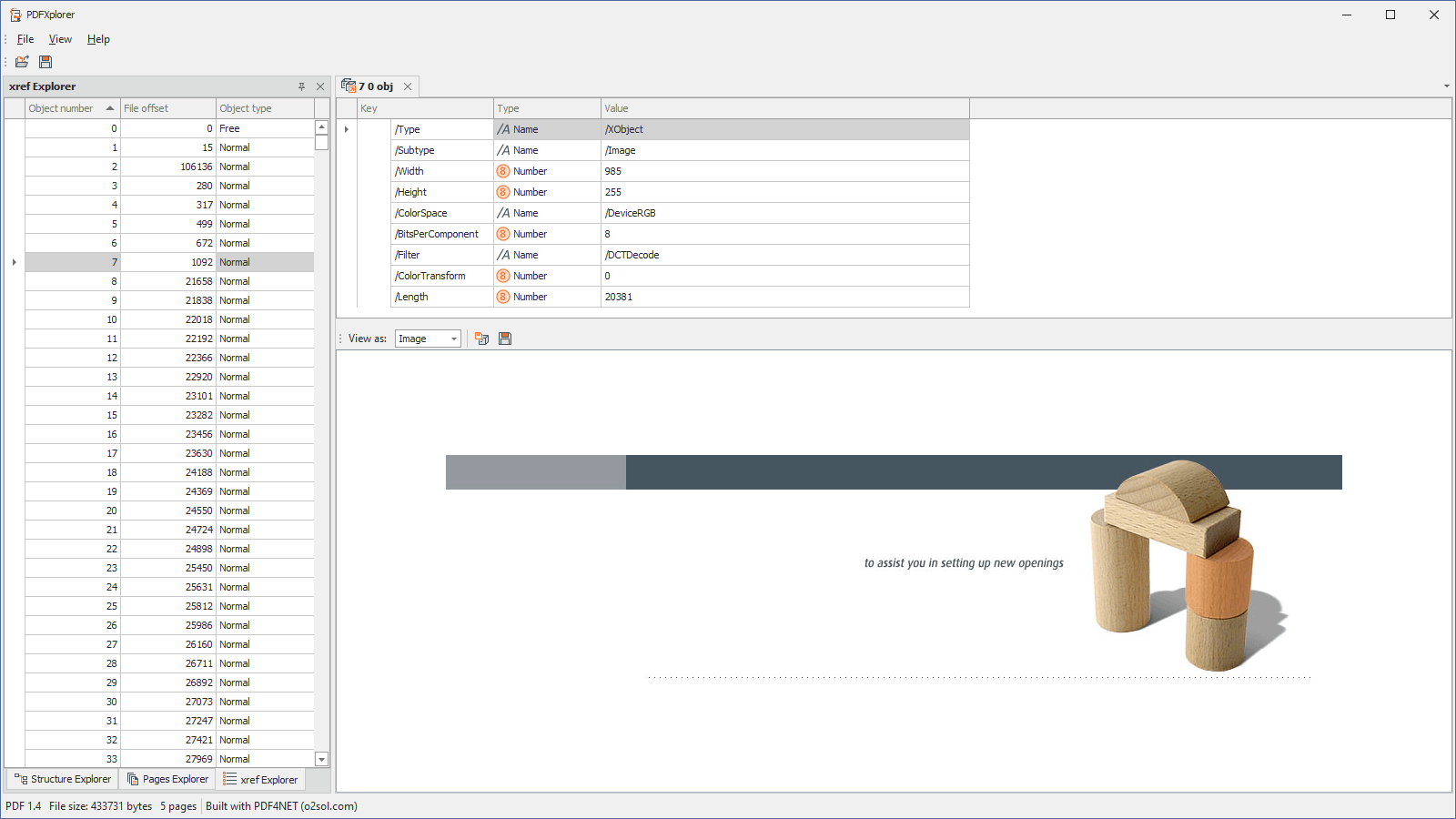
- View streams as text, binary hex or images
- Syntax highlighting with section folding for content streams, JavaScript streams, XML streams and ToUnicode Cmap streams
- Info tips for PDF operators in content streams
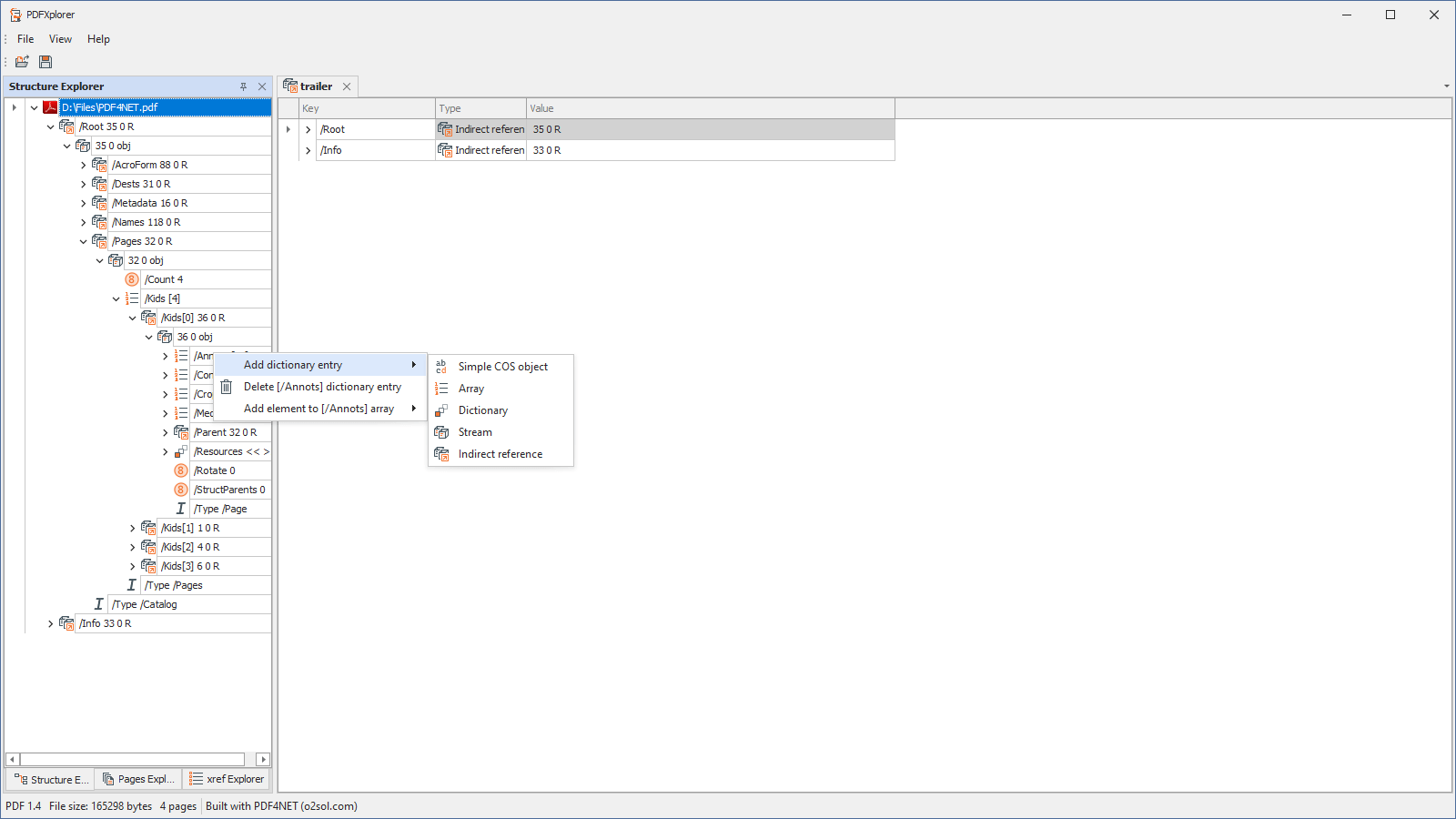
- Add/remove COS objects
- Edit COS objects (strings, names, numbers and bools)
- Merge multiple page content stream objects into a single one
- View the cross reference section in xref Explorer
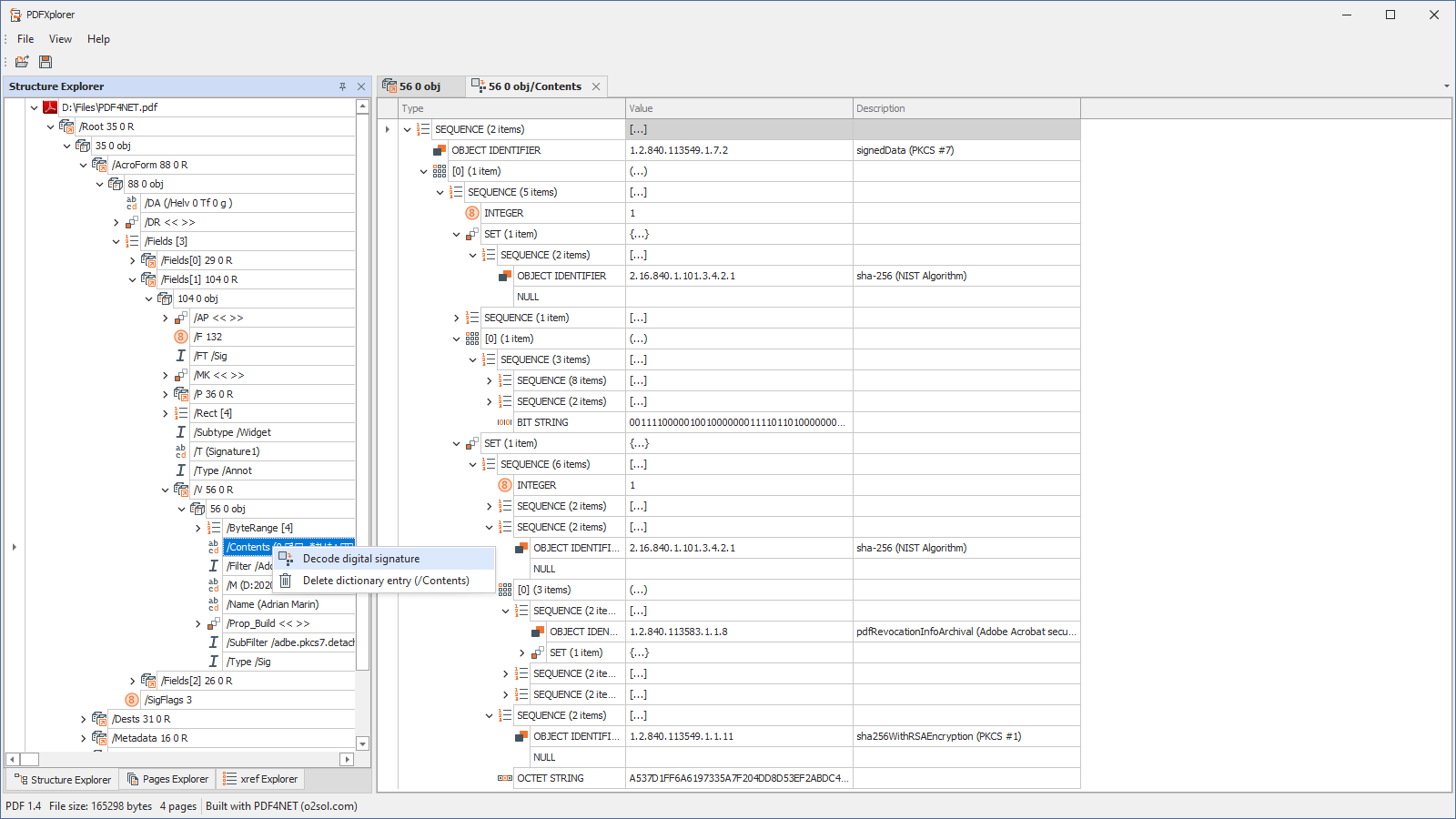
- Decompose digital signatures as ASN1. objects
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

High Level Features
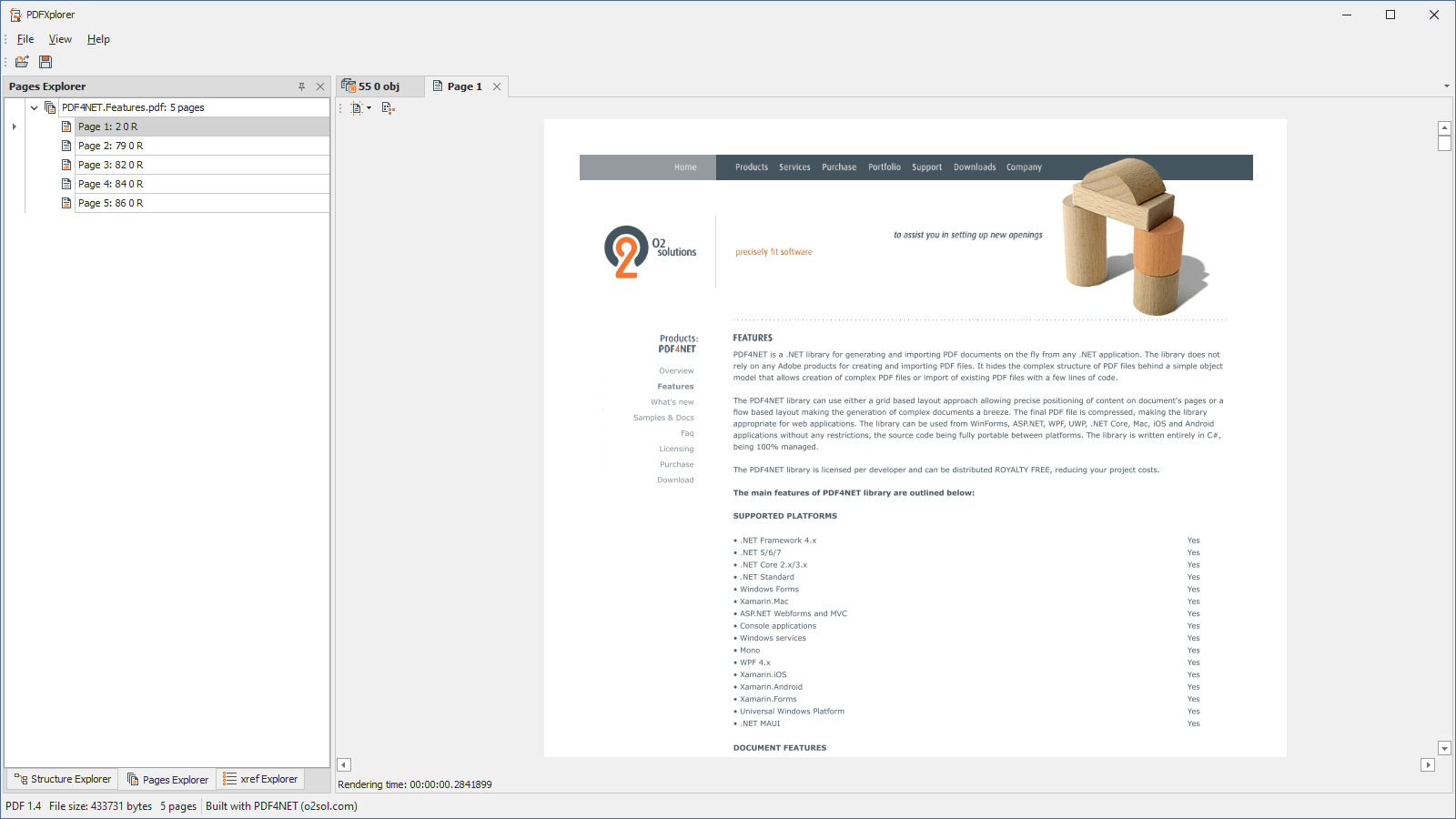
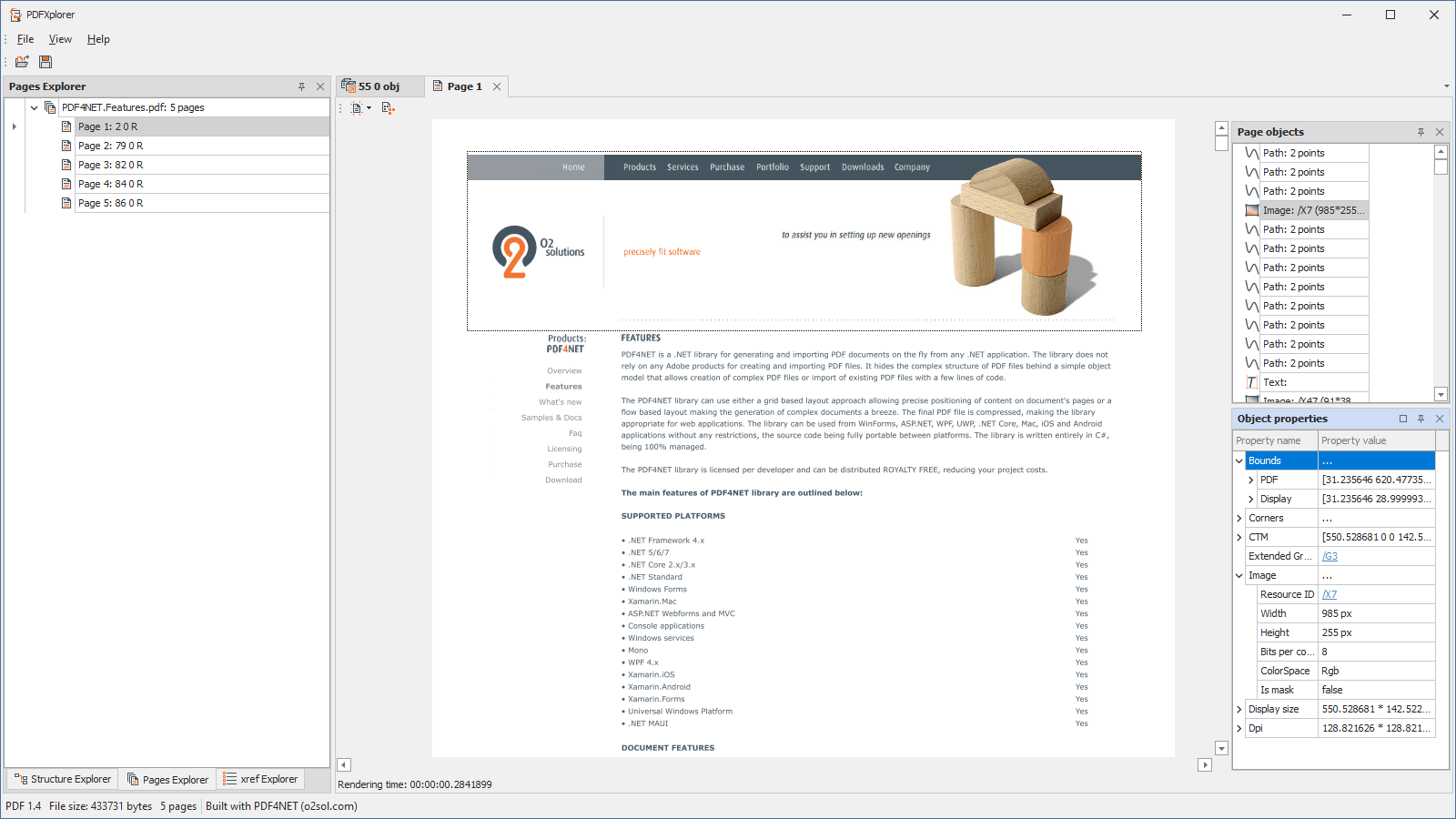
- View PDF pages in Pages Explorer
- Save PDF pages as images
- Quickly locate in Structure Explorer the page selected in Page Explorer
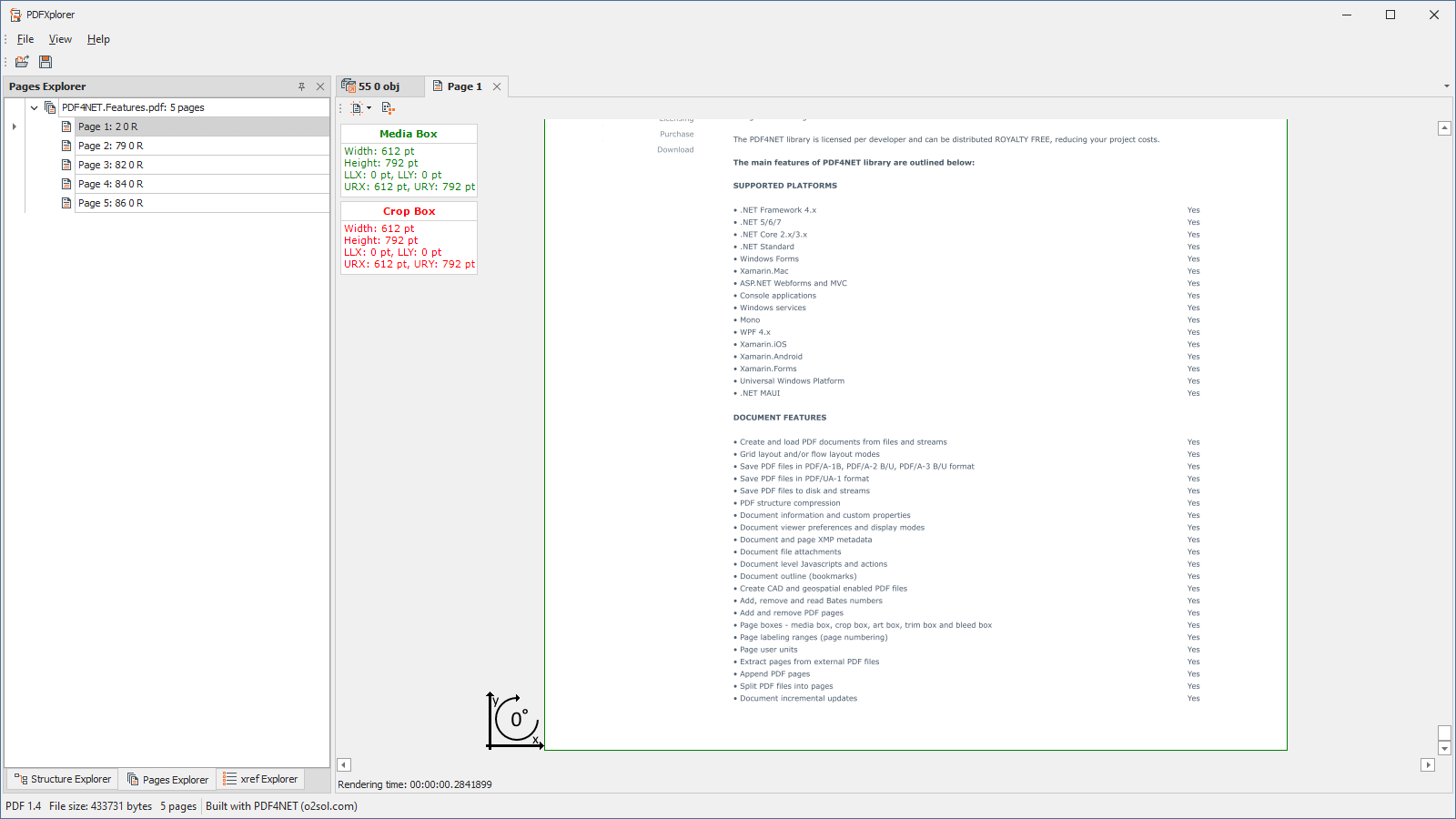
- View information about page boxes and page rotation
- View page content as a list of graphic objects
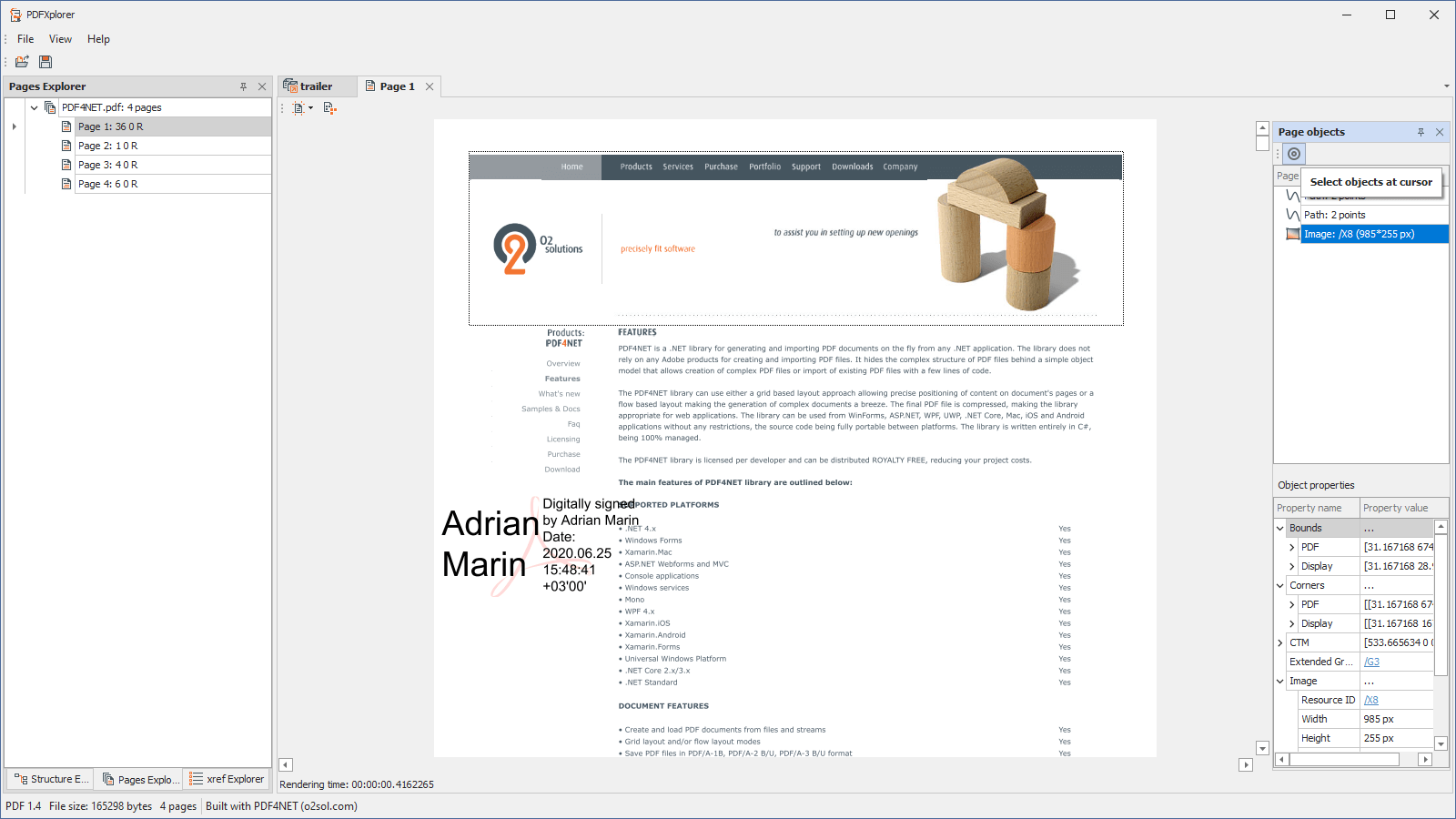
- Select page objects under mouse cursor
- View detailed information about page objects such as position, size, current matrix, fill, stroke, etc
- Resources used by page objects are displayed as link for quick navigation in the Structure Explorer
- Click an object in the list and see it selected on the page
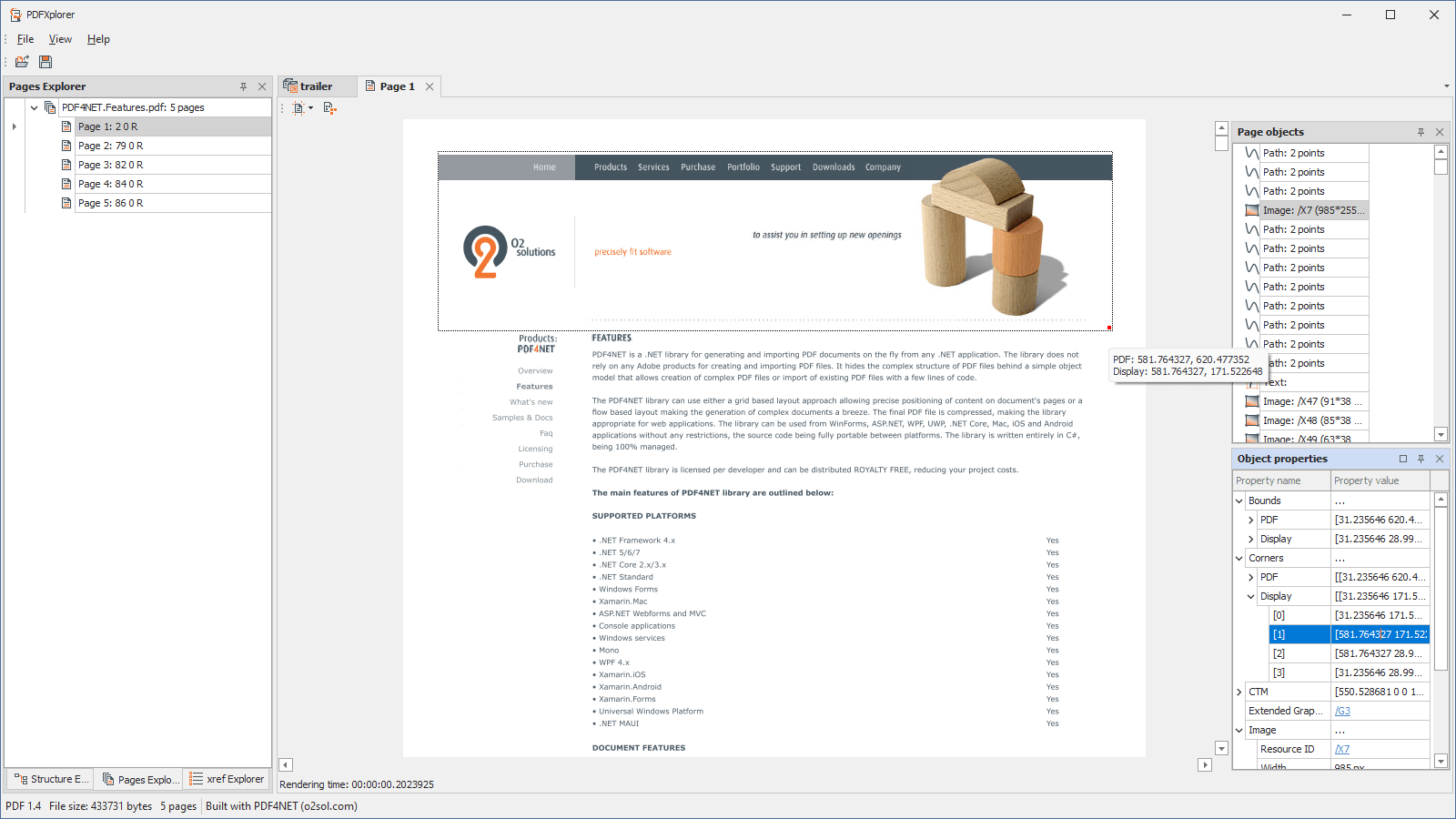
- Click on object points and see that points on the page
- Path objects display the points that compose each path section
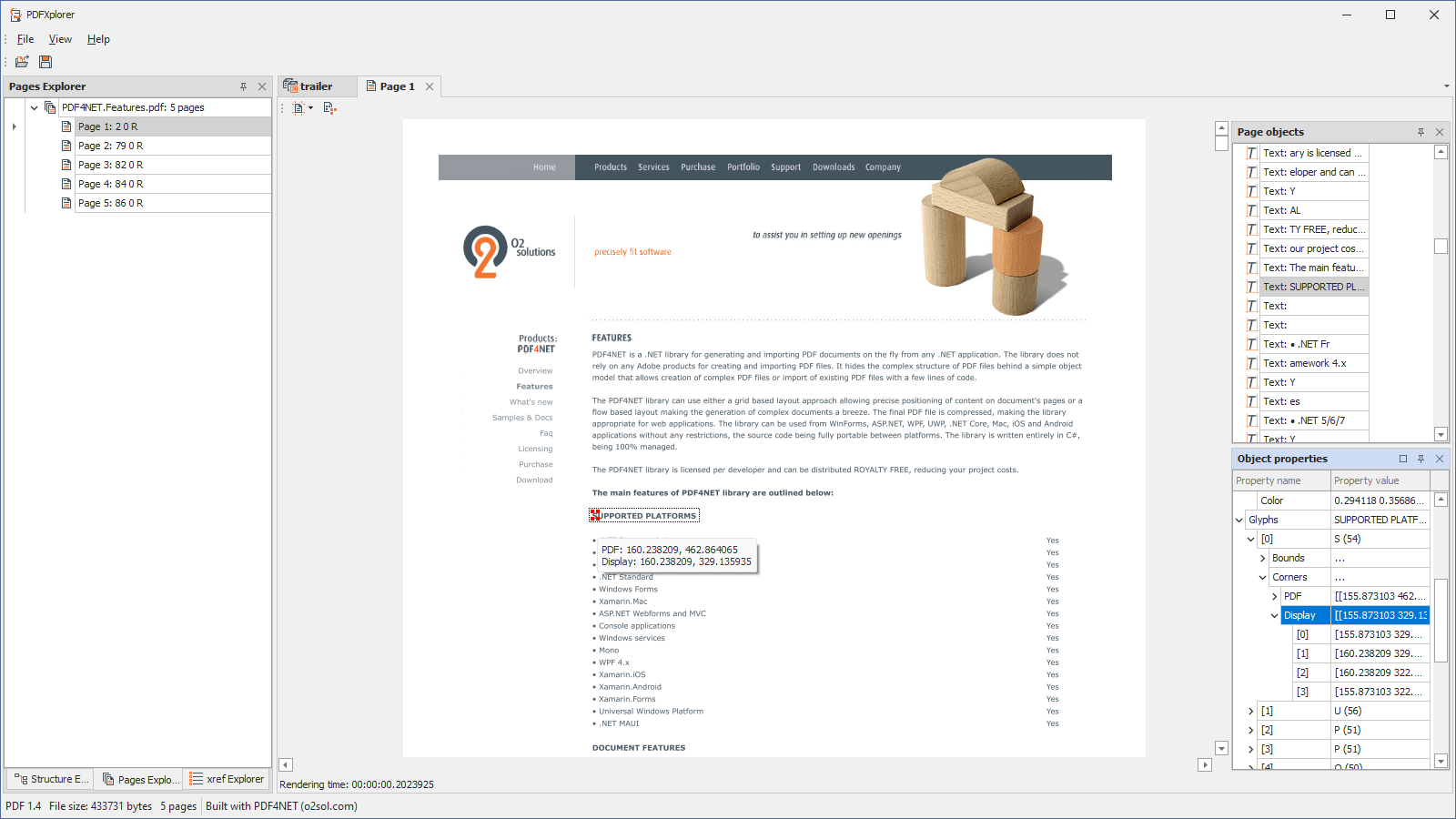
- Text objects can be split in glyphs to see the position of each glyph
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}